At University of Maryland, we are migrating from a local MS Access database appropriately named the Beast. We chose to begin our migration project with our accessions data. To get this data into ArchivesSpace we decided to use the csv importer since it seemed to be the easiest format to crosswalk our data to, and honestly, the only option for us at the time.

Okay. Let me catch my breath.
For us, it seemed that the lowest barrier for getting our accession data into ArchivesSpace was to use the csv importer. Since we could get our data out of the Beast in a spreadsheet format, this made the most sense at the time. (Oh, if we had only known.)
Our data was messier than we thought, so getting our data reconciled to the importer template had its fair share of hiccups. The clean-up is not the moral of this story, although a bit of summary may be useful: some of the issues were our own doing, such as missing accession numbers that required going back to the control files, and just missing data in general. Our other major issue was understanding the importer and the template. The documentation contained some competing messages regarding the list of columns, importance (or unimportance) ofcolumn order, as well as unanticipated changes to the system that were not always reflected in the csv importer and template We did finally manage to get a decent chunk of our data cleaned and in the template after almost a year of cleaning and restructuring thousands of records.
AND THEN. Just when we thought we had it all figured out, ArchivesSpace moved processing/processing status from collection management to events. Unfortunately, at the current time there is not a way to import event information via the CSV importer. So we were stuck. We had already invested a lot of time in cleaning up our accessions data and now had a pretty important piece of data that we could no longer ingest in that same manner.
In comes the ArchivesSpace API to save the day!!
[In hindsight, I wish we had just used the API for accessions in the first place, but when this process began we were all just wee babes and had nary a clue how to really use the API and really thought the csv importer was the only option for us. Oh how far we’ve come!]
So, we revised our process to:
- Clean accessions in excel/open refine
- Keep the processing data we would need to create the event record in a separate sheet to keep the data together
- Import accessions (minus the processing event info) using csv importer
- After successful import, have a bright-eyed student worker (thanks Emily!) do the thankless task (sorry Emily!) of recording the ID of each accession (which the API will need to associate the processing event with the correct accession) into that separate sheet mentioned in step 2
- Using the spreadsheet from step 4 as the source, create a spreadsheet that includes the accession id and associated processing status with the rest of the information required for importing events (Getting to know the various ArchivesSpace data schemas is important). To make life easier, you may want to just name the columns according to the schema elements to which they will map.
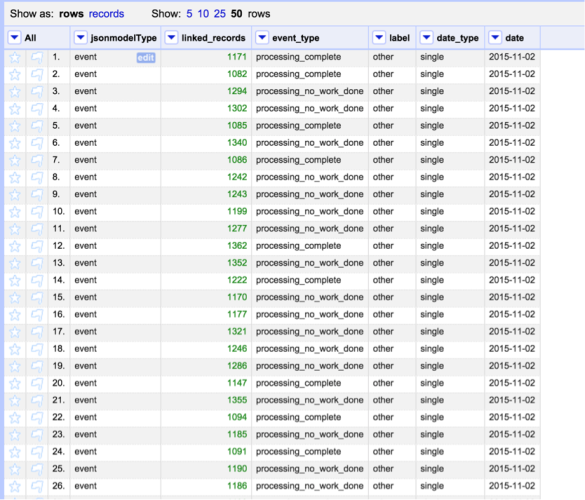
- Since the API wants this to be in a JSON file, I then upload this spreadsheet file into OpenRefine (see screenshot above). This gives me a chance to double check data, but most importantly, makes it REALLY easy for me to create the JSON file (I am not a programmer).
- Once I am happy with my data in OpenRefine, I go to export, templating, then I put in the custom template (see below) I’ve created to match data schemas (listed in step 5). Since some is boilerplate, I didn’t need to include it in the spreadsheet.
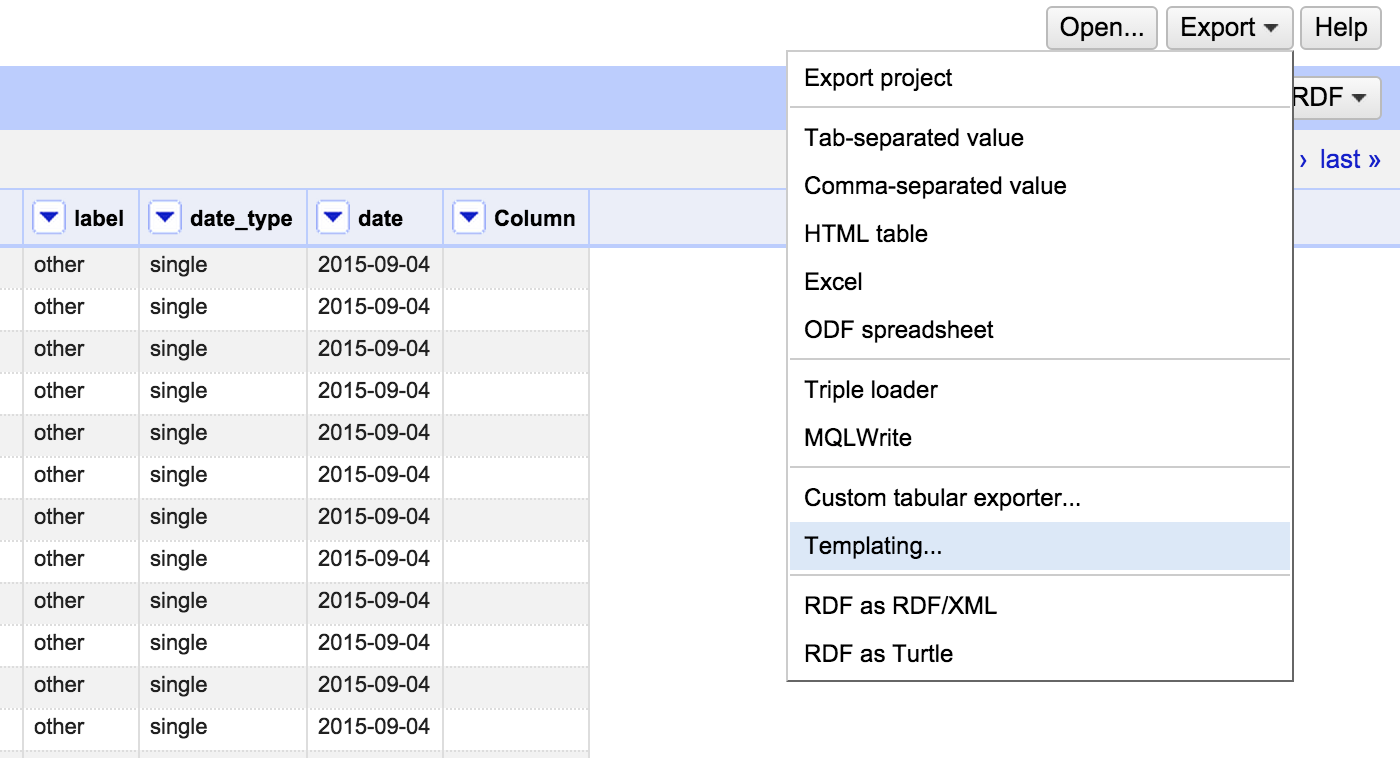
Here’s the template I developed based on the schemas for event, date, and linked records:
{"jsonmodel_type":{{jsonize(cells["jsonmodelType"].value)}},"event_type":{{jsonize(cells["event_type"].value)}},"external_ids":[],"external_documents":[],"linked_agents":[{"role":"executing_program","ref":"/agents/software/1"}],"linked_records":[{"role":"source","ref":"/repositories/2/accessions/{{jsonize(cells["linked_records"].value)}}"}],"repository":{"ref":"/repositories/2"},"date":{"label":{{jsonize(cells["label"].value)}},"date_type":{{jsonize(cells["date_type"].value)}},"expression":{{jsonize(cells["date"].value)}},"jsonmodel_type":"date"}}
Then export! Make sure to save the file with a memorable filename.
I then open the file in a text editor (for me, TextWrangler does the trick) and I have to do two things: make sure all whitespaces have been removed (using find and replace), and make sure there is one json per line. (regex find and replace of \r). However, you should be able to create the template in such a way as to do this.
Then, I put together a little bash script that tells curl to take the json file that was just created, read it line by line and POST each line via the API.
#!/bin/bash url="http://test-aspace.yourenvironment.org:port/repositories/[repo#]/event" for line in $(cat your_events.json); do echo `curl -H "X-ArchivesSpace-Session: $TOKEN" -d "$line" $url`; done
Now, I just transfer need to transfer both the bash script and the json file from my local files to the archivespace server. (using the command scp <filename> <location>. If you’re like me, you may have needed to ask a sysadmin how to do this in the first place).
Make sure you have logged in, and exported the Session ID as a $TOKEN. (I won’t walk you through that whole process of logging in, since Maureen outlines it so well here, as does the the Bentley here.)
Now, from the command line, all you need to do is:
bash curl_json.sh
And there you go. You should see lines streaming by telling you that events have been created.
If you don’t…or if the messages you see are of error and not success, fear not. See if the message makes sense (often it will be an issue with a hard-to-catch format error in the json file, like a missing semi-colon, or an extra ‘/’ (I speak from experience). These are not always easy to suss out at first, and trust me, I spent a lot of time with trial and error to figure out what I was doing wrong (I am not a programmer, and still very, very new at this).
Figuring out how to get our processing event data into ArchivesSpace after hitting a major roadblock with the csv importer still feels like a great accomplishment. We were initially worried that we were going to have to either a) go without the data, or b) enter it manually. So to find a solution that doesn’t require too much manual work was satisfying, professionally speaking (did I mention I’m not a programmer and had never really dealt with APIs before?).
So to all of you out there working in ArchivesSpace, or in anything else, and you feel like you keep hitting a wall that’s a bit higher than what you’ve climbed before, keep at it! You’ll be amazed at what you can do.

I’ve found jq a very handy tool for figuring out the ArchivesSpace API: https://stedolan.github.io/jq/ . You can easily pretty print JSON from ASpace, or with the ‘-c’ (compact) switch, it’ll un-prettify it and remove the whitespace. More involved, but you can also also modify the JSON, and send it back to ASpace.